Logs
To see logs from all pods for a specific deployment you can use:
kubectl logs -f deployment/serverTo see all deployments:
kubectl get deploymentRunning processes (or not running)?
The following command will show all running pods.
kubectl get podsTo see more details about a specific pod, run the following command:
kubectl describe pods NAME-OF-PODLicense is not a valid license
A fresh installation does not come with a license. If you need a license, reach out to us. We will supply one alongside instructions on how to use it.
Timezones
ftrack requires the timezone to be UTC. Docker containers in a Kubernetes cluster will be UTC by default. The server running MariaDB must also be set to UTC.
Verify connection to database
If you are unsure if the connection to the database works from within the cluster, you can run a container interactively and test from it:
kubectl run mariadb -i --tty --image=mariadb:10.3 --restart=Never --rm -- /bin/bashAfter a few moments you should have a bash shell, where you can run something like the following:
mysql -h IP_ADDRESS_OF_MARIADB -u ftrack_user -p -e 'select username from ftrack.user'Pod scheduling failure
If pods fail to schedule and are stuck in pending status when running, run the following command:
kubectl get podsThen describe the pod to see why the pods are stuck:
kubectl describe pods NAME-OF-PODThe output will show events at its end. If you see something like insufficient memory or CPU that means there is not enough room for this pod in your cluster, and that you need more resources.
Clustering and HA
We recommend that you run ftrack on multiple nodes as a cluster, with the master separate. We suggest this as, with this setup, a cluster can survive lost nodes, and any services on that node will simply be rescheduled onto another node. This approach means only short, partial downtime if a node goes down. A cluster will also survive losing its master for some time. With the master gone, the other nodes will continue to operate, but they won't be able to make changes or restore service if anything else fails as the master is responsible for the internal API. As such, a cluster dedicated to ftrack does not have to be HA (high availability) via using several masters, as it will withstand the most common failure scenarios with a single master.
Kubernetes maintenance
ftrack should run on any recent and maintained Kubernetes version. Nevertheless, upgrading the cluster should be performed with care and should always be tested on a staging cluster before upgrading production. The system owner is responsible for upgrading and maintaining the system and Kubernetes cluster. A Kubernetes distribution like k3s is simpler and easier to maintain as it is a single binary. A setup with kubeadm is more flexible but also requires more knowledge regarding the system and Kubernetes.
Ingress
By default, ftrack will add an ingress resource which is responsible of terminating ssl and routing traffic to the internal ftrack service. If your cluster does not support an ingress or you want to configure it differently, you can disable the ftrack ingress with:
ingress:
enabled: falseAnd then add your own kubernetes resources to the namespace to handle incoming traffic.
You can also configure the ingress and corresponding service according to your cluster requirements. Here is an example where a custom annotation is added to the ingress and the service is modified to be of type NodePort and use a specific port:
ingress:
annotations:
my-custom-annotation: "value"
service:
type: NodePort
nodePort: 33056Load balancing
Traffic to ftrack can reach ftrack via any node in the cluster. If you have a multi node cluster you should consider having some type of load balancer in front of it to distribute traffic evenly. There are many different ways to achieve this, where the simplest form of load balancing is achieved by pointing the ftrack DNS record to multiple ip addresses of the cluster nodes.
Internally in kubernetes traffic is distributed between the nodes even if they enter the cluster using the same node.
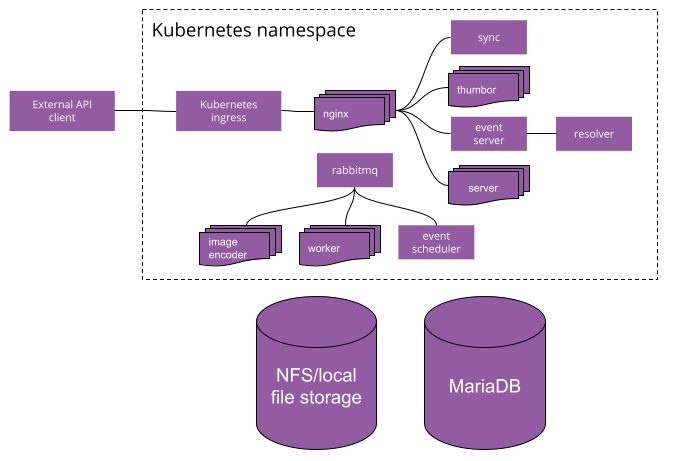
What are the different ftrack services in Kubernetes and how are they used?
Here is a list of the services that together are ftrack. They are deployed in Kubernetes as Deployment objects.
- server - General API service. This is the main ftrack service.
- event-server - Websocket server representing the event hub in the API clients.
- rabbitmq - Message broker used to communicate between services.
- nginx - Used as reverse proxy in front of the other services.
- thumbor - Image scaling service.
- sync - Websocket server that handles synced reviews.
- worker - Processes long running jobs such as encoding, exports and notifications.
- image-encoder - Converts files to images.
- resolver - Translates desktop disk file paths in the web UI.
- event-scheduler - Schedules actions such as email digests.
Missing configuration options
What if you are not able to configure something that is important?
Reach out to support@ftrack.com and make a feature request for it. We will consider all requests that come in and add it if we think it is useful for everyone.
Why is the database server not part of the cluster?
There are a few reasons why we recommend having the database server separate from the cluster.
- It requires dedicated resources and should not compete with other processes for them.
- Containers are ephemeral, which means they can be killed and recreated at any time (in theory at least). This is fine for a lot of services but can be very disruptive for a database server backed by persistent storage.
- The database need access to fast storage, which is harder to setup in a cluster.
There are however no limitations that require the database to run outside of the cluster.
Migration from Centos 6 setup
Read about how to migrate from Centos 6 in this guide.
What Linux distribution should I use?
With the new Kubernetes based deployment, ftrack is no longer dependant on a certain distribution of Linux. When setting up your Kubernetes cluster you can use any Linux distribution of your choice that is supported by the Kubernetes distribution you are using. At ftrack we still recommend using CentOS/REHL 7 if you are not sure what to use, but its important to know that it is end of life June 30 2024 and you need to switch to something else before that. Centos 8 should not be used since it is end of life 31 December 2021.
Why Kubernetes?
Kubernetes has been in use for many years. As early adopters of Kubernetes for ftrack’s cloud infrastructure, we’ve long been impressed by the technology. When researching the new on-prem installation package, we investigated and tested many different technologies and approaches, but Kubernetes remained the best tool for the job. Kubernetes provides the flexibility and features that studios need and has become the standard for container orchestration.
Historically, Kubernetes proved challenging to set up and maintain, but more tools and documentation have come into place that make things much more straightforward. Also, more lightweight and certified Kubernetes distributions have surfaced, which allow for simple one-click installations and upgrades. We’ve also watched as increasingly more enterprises have adopted a Kubernetes cluster running in their data center, which simplifies the set up ftrack as there is no need to provision new hardware.
Docker containers are the base of the new on-prem installation setup. They provide flexibility and ease of use, as they abstract away the underlying OS for services and enable applications to run anywhere.
Kubernetes also provides an array of features when it comes to availability and redundancy. Kubernetes can auto-scale based on resource usage and heal services by restarting them if they start to behave incorrectly. All excellent news for ftrack users!
Kubernetes also makes it easy to add more tools on top of ftrack, so you can handle logging and metrics in a way that works for you.
Why helm?
Software distribution, like ftrack, is often built around multiple applications working together, such as Nginx, RabbitMQ, and so forth. This approach posits individual configurations per application, each of which must be maintained and customized. Using multiple applications in this manner can snowball into a significant problem, both for end-users, as they need to know and understand more about the application and keep their configurations updated between releases, and for us as developers at ftrack when providing a new release.
The new ftrack on-prem installation package uses Helm 3 to solve these problems. Helm is a Kubernetes package manager, or in other terms, a templating tool that allows a single configuration file to drive all configuration in the ftrack service. Using Helm means no more patching of individual files and keeping track of those changes. Instead, a single file contains just the few configuration options required for your ftrack installation.
Need help and support with Kubernetes?
For simple installations and maintenance of Kubernetes we recommend using K3s from Rancher who is part of SUSE. Rancher provide 24/7 support for their Kubernetes distributions including K3s.
Glossary
If you are not familiar with Kubernetes and associated terms such as “pod” or “node”, then you can reference the Kubernetes glossary here: https://kubernetes.io/docs/reference/glossary